
¿Qué es Screamingfrog?
Screamingfrog es una herramienta que permite rastrear URLs para analizar y auditar cualquier aspecto técnico de una web. Simula a un crawler y su uso es muy extendido en el mundillo del SEO, aunque lo que se desconoce es el gran abanico de posibilidades que ofrece esta herramienta para cualquier campo dentro del marketing digital y todo aquello que esté relacionado con el entorno web. ¡No te preocupes si no tienes conocimientos técnicos, con seguir esta guía paso a paso podrás conseguirlo!
Actualmente existe una versión gratuita que permite crawlear hasta 500 URLs. De lo contrario, podéis contratar una licencia con ellos por £149 al año. Necesitarás comprar la licencia para poder scrappear datos de la web ya que esta funcionalidad está disponible sólo para aquellos que apoquinen 💸
Primeros pasos con la herramienta y setup
Descarga del software desde la web oficial 🐸
Para descargarnos Screamingfrog tendremos que acceder a su web oficial y descargarnos el software oficial. También podréis descargároslo a través del siguiente enlace.
Crédito imagen: Screamingfrog
Cómo configurar Screamingfrog para extraer valores
Una vez nos hemos descargado Screamingfrog, tendremos que configurar correctamente las reglas para extraer los valores que necesitamos. Para ello, debemos seguir los siguientes pasos:
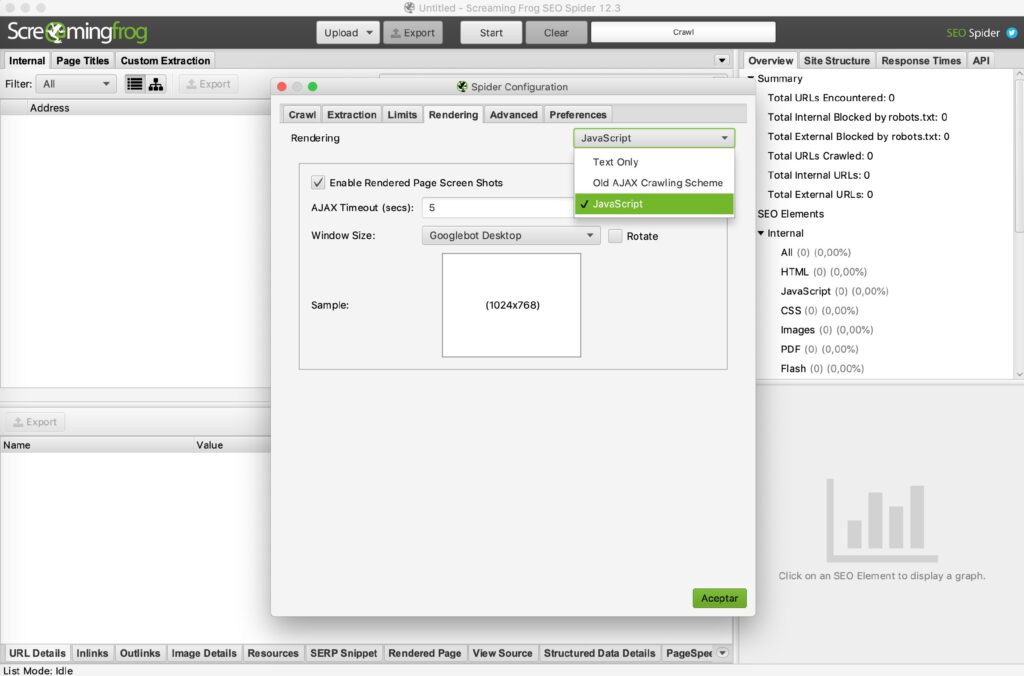
Configuración del renderizado para que sea JavaScript
Hablando en plata y sin meternos en palabrejos, necesitaremos configurar Screamingfrog con renderizado de JavaScrip básicamente porque en el código fuente de una página (lo que un crawler escanea en una web) no veremos abolutamente todos los valores de una web ya que muchas de las funcionalidades o información que tiene una landing o web se encuentra implementado con JavaScript. En resumidas cuentas, debemos incluir la funcionalidad de renderizado de JavaScript porque de esta forma podremos ver todo el contenido dinámico cargado en una web. De lo contrario, cualquier intento de renderizar contenido dinámico en Screamingfrog no servirá de nada y la herramienta nos devolverá los campos sin valores.
Para configurar esta funcionalidad en Screamingfrog debemos seguir los siguientes pasos:
Configuration > Spider > Rendering > JavaScript
Custom extraction rules: Cómo definir la info que queremos obtener
El primer paso en las custom extraction rules es copiar el path donde está indicada la información que queremos obtener de la o las URLs específicas.
Hay 3 formas distintas de indicar las rutas que necesitamos scrappear, dependiendo de cómo esté configurada la web que deseamos analizar.
- XPath: XPath es un lenguaje que selecciona los nodos de un documento HTML. Gracias a esta funcionalidad, podremos copiar el path de cualquier valor implementado, incluyendo atributos.
- Regex o regular expressions: Podremos matchear ciertos patrones en una web a través de expresiones regulares. Normalmente se suele emplear cuando necesitamos opciones más avanzadas.
- CSSPath: Dentro del CSS, podremos seleccionar patrones específicos con el CSSPath.
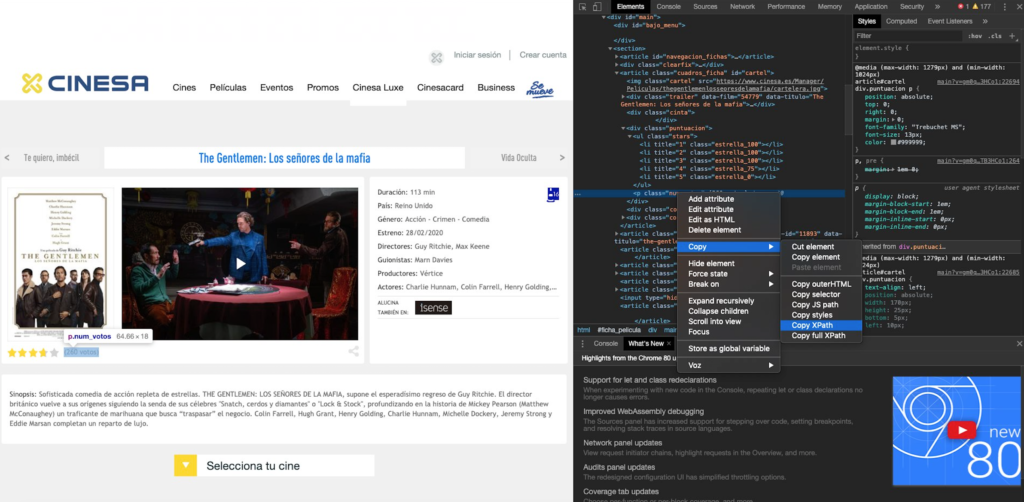
Este es un ejemplo desde la web de Cinesa, de la cual queremos extraer la info de la película, el rating actual y el número de reviews, por ejemplo.
Para copiar el path seleccionado, inspeccionaremos la página siguiendo los pasos:
Botón derecho > Inspect (la consola de Chrome se abrirá)
Seleccionar el atributo desde el cual queremos obtener la información y seguir los pasos:
Botón derecho > Copy > Copy Xpath (en este caso podemos copiar el XPath y no necesitaremos copiar ni el CSS ni usar una expresión regular)
Una vez copiemos ese valor, lo pegaremos en Screamingfrog dentro del módulo de Custom Extraction, siguiendo los pasos del siguiente apartado.
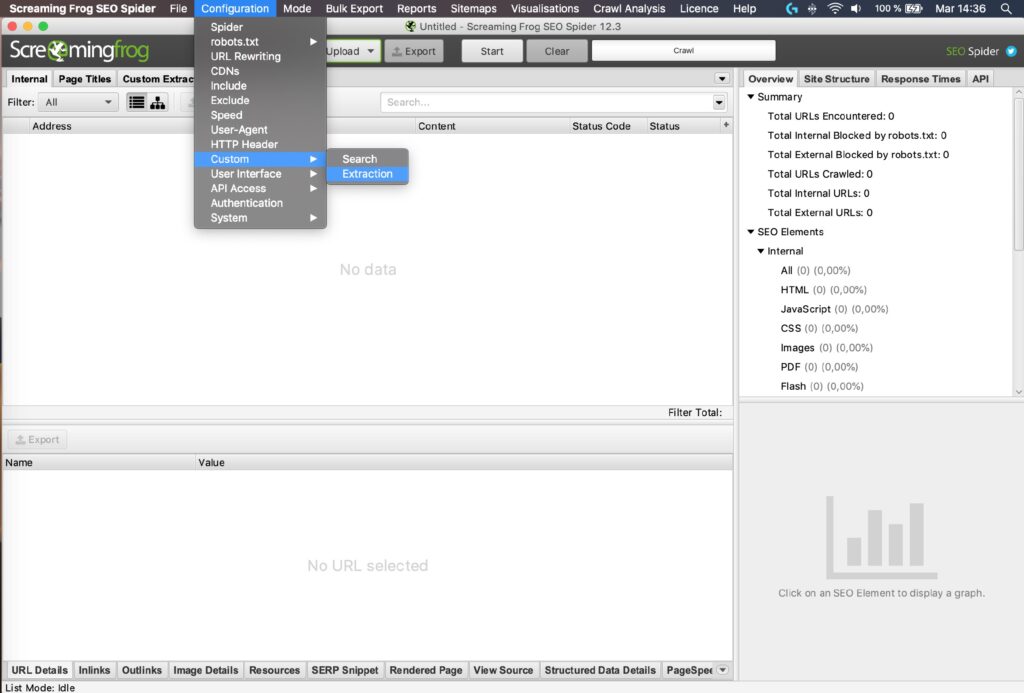
Custom extraction rules: Configuración en Screamingfrog
El segundo paso para conseguir scrappear datos de una web es configurar las custom extraction rules en Screamingfrog, analizando los XPath o rutas en la web que queremos analizar para indicarle a nuestra rana qué valores tiene que rastrear y devolver la información 🔍
Configuration > Custom > Extraction
Por otra parte, podremos filtrar específicamente qué valores queremos extraer y de qué forma:
- HTML Element: En esta opción seleccionaremos el elemento y todo el HTML que incluye dicho elemento.
- Inner HTML: Esta opción incluirá el contenido interno que incluye el HTML del elemento seleccionado.
- Text: El contenido en forma de texto del elemento seleccionado y cualquier texto que incluyan cualquier subelementos.
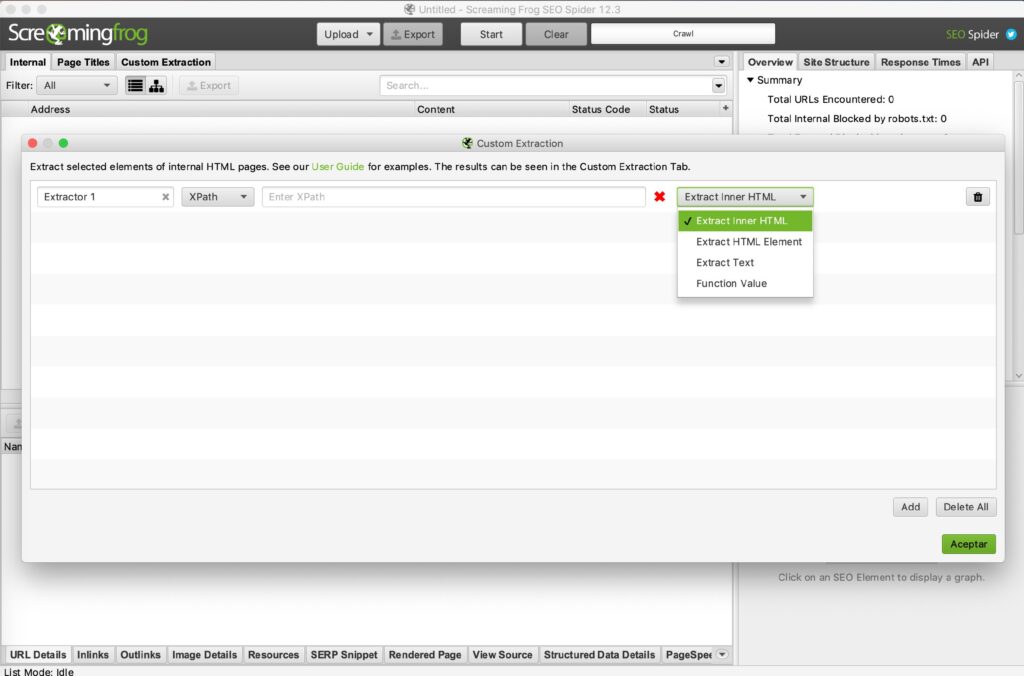
En esta página de Screamingfrog podréis consultar un montón de ejemplos e info sobre expresiones regulares más usadas y distintos ejemplos copiando XPath.
Pegar las URLs en Screamingfrog para que sean renderizadas
Hay varias formas de pegar las URLs que hemos identificado para hacer la extracción de información. Estas formas son las que están disponibles en la herramienta actualmente desde Upload. Pegaremos la o las URLs que deseemos analizar y comenzaremos con el proceso.
Una vez has pegado la URL, deberías de ver un pop up con lo siguiente:
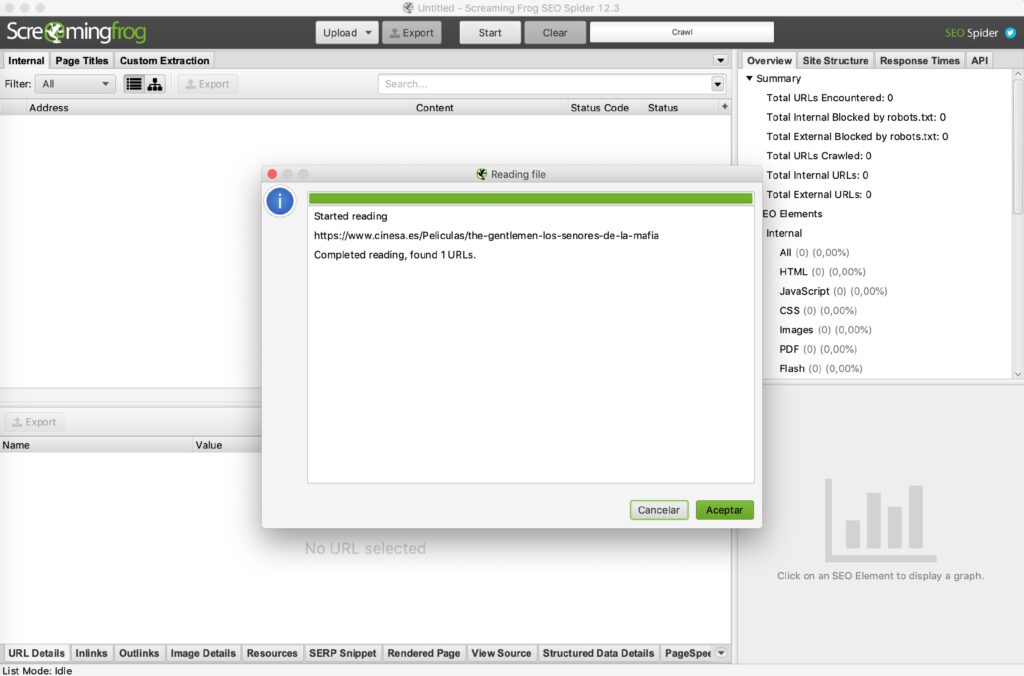
Una vez Screamingfrog haya obtenido la información, podremos descargarnos un Excel con toda la información bajo Export.
Voilà! 🎉 Ya podemos analizar la información obtenida en bulk desde Screamingfrog y jugar con todos los datos de la forma más creativa que se nos ocurra: Análisis, visualizaciones, incluirlo en nuestros data warehouses…
Resumen del proceso: Paso a paso
- Configuración de renderizado en JavaScript en Configuration > Spider > Rendering > JavaScript
- Copiar los XPaths o utilizar Regex para definir el campo que queramos que Screamingfrog scrapee analizando los atributos desde la consola de Chrome. Para ello, visitaremos la página web que queramos analizar y copiaremos el XPath Botón derecho > Inspect > Seleccionaremos el path > Copy > Copy XPath
- Pegaremos el valor del XPath o Regex en Screamingfrog en la sección Configuration > Custom > Extraction > Add para cada regla que queramos definir
- Pegaremos las URLs que queramos analizar en Upload > Paste > Start reading
- Lanzaremos la petición en Start
- Nos descargaremos todos los valores en Export
Ejemplos de análisis
Existen infinidad de formas de analizar todo lo que queramos extraer, pero aquí os dejo algunas ideas para poner en práctica:
- Análisis de precios y variaciones periódicas
- Análisis de rating y reviews de cualquier producto/comparativa
- Análisis de disponibilidad de productos en eretailers
A tener en cuenta…
Analizar el robots.txt de la página si no obtienes datos
Tenemos que tener en mente que muchas webs no permiten el scrapping y tienen cualquier bot que no sea Google y los principales bots baneados a través de su robots.txt
Volumen de peticiones y usos de los datos obtenidos
Hay que tener en cuenta que el scrapping como tal consume recursos del sistema, y que puede llegar a saturar una página y originar perjuicios al resto de usuarios o al propietario de la página dependiendo del hosting que la página web tenga contratado.
También tendremos que tener en cuenta que la propiedad de los datos, aunque los hayamos scrapeado, serán exclusivamente propiedad de los gestores de la página web y que sin su permiso no podrá ser obtenida o usada para fines comerciales.
Scrappear datos de una web sin su permiso puede ser ilegal
Esto es otro factor que debemos de tener en cuenta antes de scrappear datos de una web sin su permiso. Tendremos que verificar que la página en cuestión permite este tipo de prácticas.
Analizando el robots.txt de Facebook, podemos ver cómo esta práctica está totalmente prohibida y tendremos que obtener cualquier tipo de dato de la red social a través de su API.

¿Y a vosotros? ¿Se os ocurren más formas de poner en práctica el scrapping con Screamingfrog? ¡Cuéntanoslo aquí! 👇






")




